Lors de la 5ème édition du West Data Festival 2023, Ellie Guégan, experte chez Verteego, a captivé l’audience en partageant sa vision sur les utilisations de la data en industrie. Son intervention a permis d’approfondir notre compréhension du fonctionnement des solutions d’intelligence artificielle (IA) grâce à de nombreux cas d’usages présentés. Ces exemples concrets ont ouvert de nouvelles perspectives quant à ce que l’IA peut accomplir dans le domaine de la Supply Chain.

Amélioration des performances de la Supply Chain grâce à l’IA
Ellie Guégan a mis en lumière plusieurs cas d’usages illustrant l’impact de l’IA sur les performances de la Supply Chain. Parmi ceux-ci, trois objectifs principaux se démarquent : éviter les ruptures de stock, augmenter les ventes à plein prix et prendre en compte les spécificités géographiques. Grâce à l’analyse des données, les entreprises peuvent désormais anticiper les fluctuations de la demande, ajuster leurs stocks en conséquence et optimiser leurs opérations.
Ellie Guégan a rappelé ce que représente l’IA prédictive, basée sur le machine learning. Celle-ci joue un rôle crucial en permettant de prédire, simuler et automatiser divers aspects tels que les stocks, les prix, les promotions et l’assortiment d’une entreprise. Grâce à des espérances plus précises et à des mises à jour développées en temps réel, les entreprises peuvent planifier plus efficacement leurs ressources et éviter les excédents ou les pénuries inutiles.
Impacts positifs sur l’environnement
L’intervention d’Ellie Guegan a également mis l’accent sur les avantages environnementaux de l’utilisation de l’IA dans la chaîne d’approvisionnement. Grâce à une meilleure gestion des données, il est possible de réduire les émissions de CO2, le gaspillage alimentaire, les biens obsolètes et les émissions liées au transport. L’IA permet de prendre des décisions éclairées et d’optimiser les processus afin de minimiser l’empreinte écologique de la chaîne d’approvisionnement.
Les fondamentaux de l’apprentissage automatique
Au-delà des cas d’usages présentés, Ellie Guégan a expliqué les principes de base de l’apprentissage automatique. Elle a expliqué les différentes techniques, telles que le clustering, la classification et la régression, ainsi que leur application respective dans les tâches non supervisées et supervisées. Elle a souligné l’importance des données d’entraînement, des modèles prédictifs et des mesures de performance pour sélectionner le meilleur modèle.

L’importance de l’entraînement
En IA, il faut entraîner un modèle pour qu’il soit performant. Un modèle de droite Underfit veut dire que le modèle d’entrainement est trop simple pour capturer les relations complexes présentes dans les données.
Au contraire, un modèle de droite Overfit est trop complexe alors il s’adapte trop étroitement aux données d’entrainement (il ne se généralise pas bien sur de nouvelles données).
Il va donc falloir utiliser des méthodes pour éviter d’être Underfit et Overfit. Il va falloir diviser les modèles d’entraînement en jeu d’entraînement et jeu de test. On va entraîner le modèle sur le jeu d’entraînement et on valide la performance sur le jeu de test. Ceci va permettre de trouver son « sweet spot ». Ce dernier fait référence à un équilibre dans le choix des paramètres d’entrainement (le point ou le modèle atteint les meilleures performances en termes de précision, de généralisation et d’efficacité. Le sweet spot est atteint lorsque le modèle parvient à généraliser les motifs sous-jacents de données sans trop d’adapter aux exemples spécifiques.
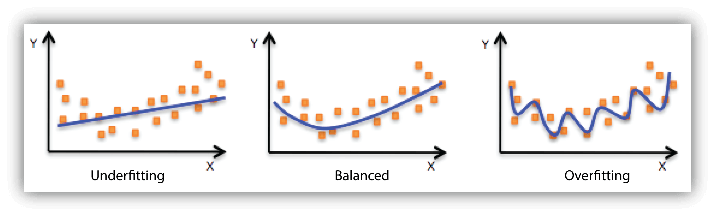
Mais quel modèle choisir pour mon entreprise ?
Ellie Guegan rappelle que lorsqu’il s’agit de choisir un modèle d’intelligence artificielle (IA) pour son entreprise, il est important de prendre en compte plusieurs facteurs tels que les caractéristiques des données, les objectifs commerciaux et les contraintes spécifiques de l’entreprise. Parmi les modèles couramment utilisés, on trouve les modèles linéaires et les modèles polynomiaux.
Modèle linéaire
Un modèle linéaire suppose une relation linéaire entre les variables d’entrée et la variable de sortie. Il essaie de trouver la meilleure ligne droite (ou hyperplan dans le cas de modèles plus complexes) qui représente les données. Les modèles linéaires sont souvent faciles à interpréter, car la relation entre les variables est directe. Ils sont relativement rapides à entraîner et à utiliser, surtout pour de grandes quantités de données. De plus, les modèles linéaires ont tendance à généraliser correctement les données et à être moins sensibles au surapprentissage.
Cependant, les modèles linéaires ne peuvent pas capturer des relations complexes et non linéaires entre les variables. Ils peuvent être insuffisamment flexibles pour des problèmes où les données présentent des motifs plus complexes.
Modèle polynomial
Les modèles polynomiaux étendent les modèles linéaires en incluant des termes de puissance supérieure des variables d’entrée. Cela permet de capturer des relations non linéaires entre les variables. Le principal avantage de ces modèles est qu’ils peuvent capturer des relations non linéaires plus complexes et ajuster les données de manière plus précise. En augmentant le degré du polynôme, le modèle peut s’adapter à des formes de données plus variées.
Cependant, l’entraînement de modèles polynomiaux de degré élevé peut être plus coûteux en termes de temps de calcul et de ressources nécessaires.
Le modèle en arbre de décision
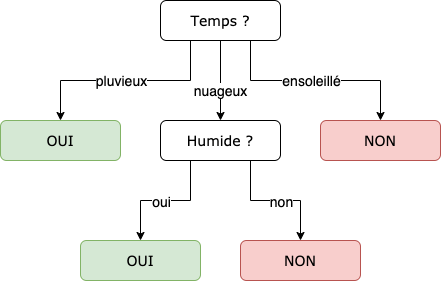
Le modèle en arbre de décision est basé sur la création d’une structure d’arbre où chaque nœud représente une décision basée sur une caractéristique des données, et chaque branche représente une valeur possible de cette caractéristique. Ce modèle divise récursivement les données d’entrée en fonction des caractéristiques les plus discriminantes.
Les arbres de décision sont facilement interprétables. Contrairement aux modèles linéaires, ils peuvent capturer des relations non linéaires entre les variables d’entrée et la variable de sortie.
En revanche, les modèles en arbre de décision peuvent facilement devenir trop complexes (overfit). Des petites variations dans les données d’entraînement peuvent conduire à des arbres de décision très différents, ce qui peut entraîner une instabilité des prédictions.
Ils peuvent avoir du mal à représenter des relations complexes qui nécessitent une combinaison de plusieurs caractéristiques.
Le choix entre un modèle linéaire, un modèle polynomial et un modèle en arbre de décision dépendra de plusieurs facteurs : nature des données, complexité du problème, objectifs de l’entreprise… Si les données montrent une relation linéaire claire, un modèle linéaire pourrait être suffisant et offrir une interprétation aisée. En revanche, si les données présentent des motifs non linéaires importants, un modèle polynomial pourrait mieux capturer ces relations complexes. Les arbres de décision, de leur côté, sont souvent utilisés lorsque l’interprétabilité du modèle est une priorité ou lorsque les données présentent des relations non linéaires importantes.
L’importance de la profondeur des données et de la hiérarchie dans la Supply Chain
Un point clé de l’intervention d’Ellie Guégan a été l’importance de la profondeur des données. Plus les informations requises sont riches et détaillées, plus l’IA peut fournir des insights pertinents pour la Supply Chain. De plus, elle a mis en évidence la hiérarchie des données, parce que chaque niveau de la chaîne d’approvisionnement possède ses propres données spécifiques, nécessitant une analyse adaptée pour une meilleure prise de décision.
XGBoost : Une méthode populaire d’apprentissage automatique
Parmi les différentes techniques présentées, Ellie Guégan a mis en avant XGBoost, une méthode d’apprentissage automatique très populaire qui permet de corriger les erreurs des modèles. Elle a expliqué comment cette approche permet de combiner plusieurs modèles prédictifs pour obtenir des résultats plus précis. Ellie Guégan définit cet outil comme très puissant : “Il fait plein de petits modèles simples avec chaque modèle qui corrige l’erreur de modèle précédent.” Elle a souligné que XGBoost est particulièrement adapté pour la résolution de problèmes complexes de la Supply Chain. En effet, elle est efficace avec les jeux de données volumineux et complexes en faisant appel à plusieurs méthodes d’optimisation.
Des cas d’usages IA Supply Chain
Ellie Guégan va prendre plusieurs cas d’usages pour illustrer ses propos notamment celui d’un leader français de la grande distribution qui voulait faire la prévision des ventes promotionnelles. Verteego a utilisé XGBoost pour améliorer leur modèle. Plusieurs types de donnés étaient prises en compte dans le modèle IA : données de magasin (affluence, trafic, parcours client…), données de ventes (panier, catalogue produits, base clients…), données externes (météo, Covid, pollution…), données géomarketing (événements, localisation…). Grâce à la prise en compte de ces données dans leur modèle IA, le leader de la grande distribution a pu optimiser ses prévisions de ventes et obtenir des insights.

Quelles limitations de l’IA dans la Supply Chain
Ellie Guégan sur les limites que représentent les IA pour la Supply Chain. Elle évoque le cas de ChatGPT : “Sur quels textes de données a-t’il été entraîné ?”. Des informations sont parfois biaisées. Cette notion de biais dans les données peut être très subtile mais très importante. Sans information ou d’historique, les algorithmes ne sont pas en mesure de vous prédire quoi que ce soit.
Le récap IA et Supply Chain
L’intervention d’Ellie Guégan de chez Verteego lors du West Data Festival a permis d’éclairer les multiples facettes de l’utilisation de la data en industrie, en mettant l’accent sur les applications de l’IA dans la supply chain. Grâce à une meilleure compréhension des usages de la data et des méthodes d’apprentissage automatique, les entreprises peuvent désormais optimiser leurs opérations, améliorer leurs performances, réduire leurs coûts et minimiser leur impact environnemental. L’intervention d’Ellie Guégan a ainsi permis d’ouvrir de nouvelles perspectives passionnantes pour le futur de la Supply Chain.
Le West Data Festival 2024
Laval Mayenne Technopole organise la 6ème édition du West Data Festival du 12 au 14 mars 2024 à l’Espace Mayenne de Laval.
Cet évènement est le rendez-vous annuel des professionnels pour découvrir, tester et apprendre autour de la gestion des données et de l’intelligence artificielle.
Ce festival évoquera plus en détails la thématique l’IA et la gestion des données au travers de conférences dirigées par des experts ainsi que des ateliers pour favoriser la discussion entre les professionnels et les festivaliers.
